OmniSVG: A Unified Scalable Vector Graphics Generation Model
NeurIPS 2025
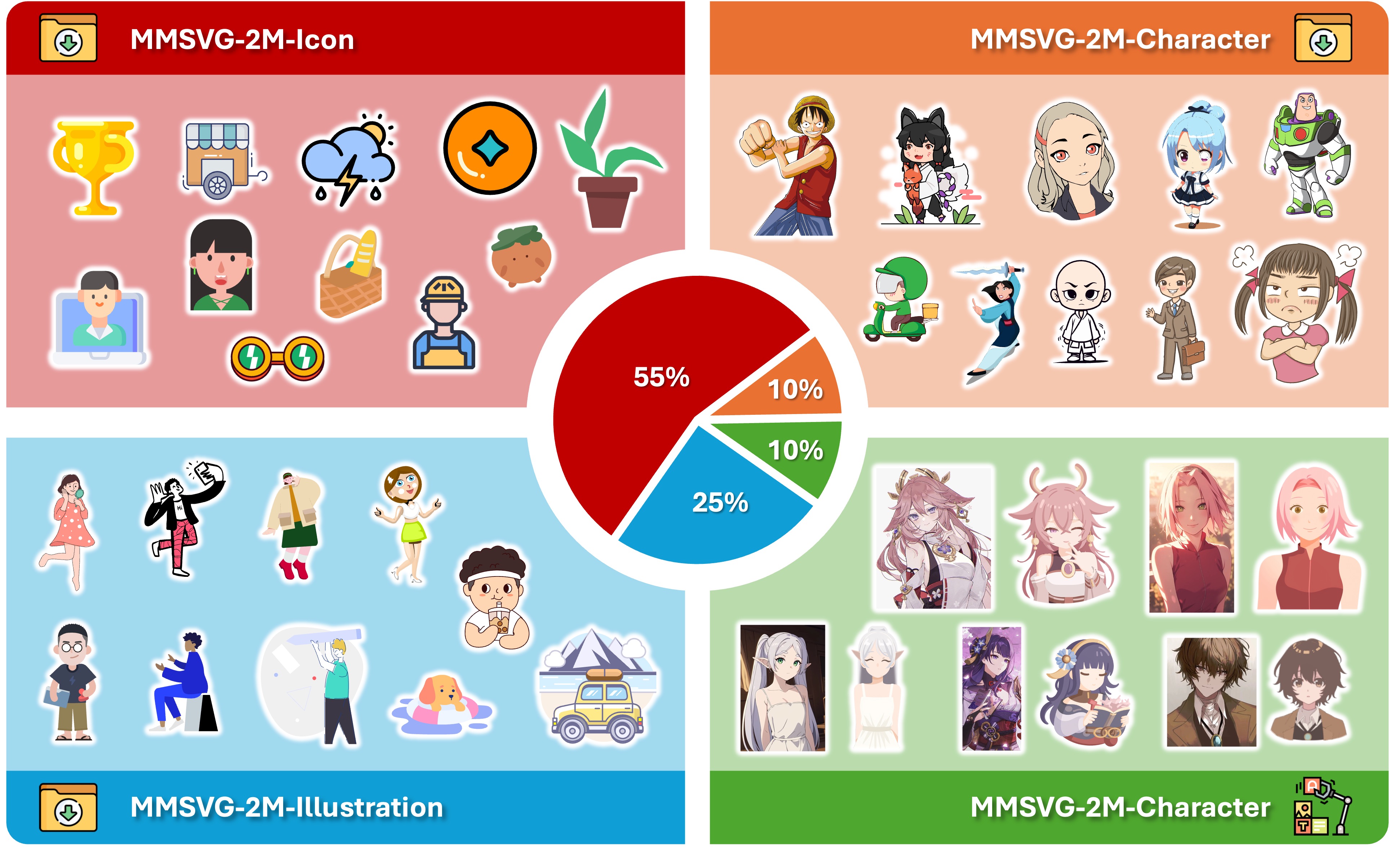
Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.



We thank the following excellent open-source works:
IconShop: is the first advanced work that leverages LLMs to generate monochrome, icon-level SVGs. We referred to its parametric implementation.
Here is the list of highly related concurrent works:
LLM4SVG: treats SVG coordinates as number strings and predicts decimal part for higher spatial accuracy.StarVector: equips LLM with an image encoder for Image-to-SVG generation.
We thank the following contributors for dataset construction and discussion: Haozhen Sun, Chengchen Wu, Panyi Yang, Ciba
@article{yang2025omnisvg,
title={OmniSVG: A Unified Scalable Vector Graphics Generation Model},
author={Yang, Yiying and Cheng, Wei and Chen, Sijin and Zeng, Xianfang and Zhang, Jiaxu and Wang, Liao and Yu, Gang and Ma, Xingjun and Jiang, Yu-Gang},
journal={arXiv preprint arXiv:2504.06263},
year={2025}
}